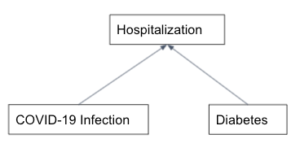
حالت چهره گامی مهم در راهپیمایی Roblox به سمت تبدیل متاورس به بخشی از زندگی روزمره مردم از طریق تعاملات طبیعی و باورپذیر آواتار است. با این حال، متحرک سازی چهره های شخصیت های سه بعدی مجازی در زمان واقعی یک چالش فنی بسیار بزرگ است. علیرغم پیشرفتهای تحقیقاتی متعدد، نمونههای تجاری محدودی از برنامههای انیمیشن چهره در زمان واقعی وجود دارد. این به ویژه در Roblox چالش برانگیز است، جایی که ما از مجموعهای گیجکننده از دستگاههای کاربر، شرایط دنیای واقعی و موارد استفاده بسیار خلاقانه توسعهدهندگان خود پشتیبانی میکنیم.
![]()
![]()
در این پست، ما یک چارچوب یادگیری عمیق برای پسرفت کنترلهای انیمیشن صورت از ویدیو را شرح میدهیم که هم به این چالشها میپردازد و هم ما را در برابر تعدادی از فرصتهای آینده باز میکند. چارچوب توضیح داده شده در این پست وبلاگ نیز به عنوان یک ارائه شده است صحبت at SIGGRAPH 2021.
انیمیشن صورت
گزینه های مختلفی برای کنترل و متحرک سازی یک فیس ریگ سه بعدی وجود دارد. سیستمی که ما استفاده می کنیم Facial Action Coding System یا نامیده می شود FACS، که مجموعه ای از کنترل ها را (بر اساس قرارگیری عضلات صورت) برای تغییر شکل مش سه بعدی صورت تعریف می کند. علیرغم اینکه بیش از 3 سال سن دارد، FACS هنوز هم استاندارد واقعی است زیرا کنترل های FACS بصری هستند و به راحتی بین دکل ها قابل انتقال هستند. نمونه ای از دکل FACS در حال تمرین را می توان در زیر مشاهده کرد.
![]()
روش
ایده این است که روش مبتنی بر یادگیری عمیق ما یک ویدیو را به عنوان ورودی گرفته و مجموعه ای از FACS را برای هر فریم خروجی بگیرد. برای رسیدن به این هدف، از معماری دو مرحله ای استفاده می کنیم: تشخیص چهره و رگرسیون FACS.
![]()
شناسایی چهره
برای دستیابی به بهترین عملکرد، یک نوع سریع از الگوریتم تشخیص چهره نسبتاً شناخته شده MTCNN را پیاده سازی می کنیم. الگوریتم اصلی MTCNN کاملاً دقیق و سریع است، اما به اندازه کافی سریع نیست که از تشخیص چهره در زمان واقعی در بسیاری از دستگاههای مورد استفاده کاربران ما پشتیبانی کند. بنابراین برای حل این مشکل، الگوریتم مورد استفاده خاص خود را بهینهسازی کردیم، زمانی که یک چهره شناسایی شد، پیادهسازی MTCNN ما فقط آخرین مرحله O-Net را در فریمهای متوالی اجرا میکند که منجر به افزایش سرعت متوسط 10 برابری میشود. ما همچنین از نشانههای چهره (محل چشمها، بینی و گوشههای دهان) پیشبینیشده توسط MTCNN برای تراز کردن جعبه محدودکننده صورت قبل از مرحله رگرسیون بعدی استفاده میکنیم. این همترازی امکان برش دقیق تصاویر ورودی را فراهم میکند و محاسبات شبکه رگرسیون FACS را کاهش میدهد.
![]()
رگرسیون FACS
معماری رگرسیون FACS ما از یک راهاندازی چند وظیفهای استفاده میکند که با استفاده از یک ستون فقرات مشترک (معروف به رمزگذار) به عنوان استخراجکننده ویژگی، نشانهها و وزنهای FACS را آموزش میدهد.
این تنظیمات به ما امکان میدهد وزنهای FACS را که از دنبالههای انیمیشن مصنوعی به دست میآیند، با تصاویر واقعی که ظرافتهای حالات چهره را به تصویر میکشند، افزایش دهیم. زیرشبکه رگرسیون FACS که در کنار رگرسیون نشانهها آموزش داده شده است پیچیدگی های علی; این پیچیدگیها در طول زمان بر روی ویژگیها عمل میکنند، برخلاف پیچیدگیهایی که فقط بر روی ویژگیهای فضایی کار میکنند که در رمزگذار یافت میشود. این به مدل اجازه میدهد تا جنبههای زمانی انیمیشنهای صورت را بیاموزد و حساسیت آن را نسبت به ناهماهنگیهایی مانند جیتر کمتر میکند.
![]()
آموزش
ما در ابتدا مدل را فقط برای رگرسیون نقطه عطف با استفاده از تصاویر واقعی و مصنوعی آموزش می دهیم. پس از تعداد معینی از مراحل، شروع به اضافه کردن دنبالههای مصنوعی برای یادگیری وزنها برای زیرشبکه رگرسیون زمانی FACS میکنیم. سکانس های انیمیشن مصنوعی توسط تیم بین رشته ای ما از هنرمندان و مهندسان ایجاد شده است. یک ریگ نرمالشده برای همه هویتهای مختلف (مشهای صورت) توسط هنرمند ما راهاندازی شد که بهطور خودکار با استفاده از فایلهای انیمیشن حاوی وزنهای FACS تمرین و رندر شد. این فایلهای انیمیشن با استفاده از الگوریتمهای بینایی رایانهای کلاسیک که روی توالیهای ویدیویی چهره-کالیستنیک اجرا میشوند و با دنبالههای متحرک دستی برای حالتهای شدید چهره که در ویدیوهای کالیستنیک وجود نداشت، تکمیل شدند.
ضرر و زیان
برای آموزش شبکه یادگیری عمیق خود، چندین عبارت مختلف از دست دادن را به صورت خطی ترکیب میکنیم تا نشانهها و وزنهای FACS را به عقب برگردانیم:
- تلفات موقعیتی برای نشانهها، RMSE موقعیتهای پسرفته (Llmks ، و برای وزن های FACS، MSE (Lچهره ها ).
- زیان های زمانی برای وزنهای FACS، با استفاده از تلفات زمانی نسبت به دنبالههای انیمیشن مصنوعی، لرزش را کاهش میدهیم. کاهش سرعت (Lv ) الهام گرفته از [کودیرو و همکاران 2019] MSE بین سرعت های هدف و پیش بینی شده است. این نرمی کلی عبارات پویا را تشویق می کند. علاوه بر این، یک اصطلاح منظم سازی بر روی شتاب (LACC ) برای کاهش لرزش وزنه های FACS اضافه می شود (وزن آن برای حفظ پاسخگویی پایین نگه داشته می شود).
- از دست دادن ثبات ما از تصاویر واقعی بدون حاشیه نویسی در کاهش ثبات بدون نظارت استفاده می کنیم (Lc )، شبیه به [هنری و همکاران 2018]. این امر باعث میشود که پیشبینیهای نقطه عطف تحت تغییر شکلهای مختلف تصویر معادل باشند، و سازگاری مکان نقطه عطف بین فریمها را بدون نیاز به برچسبهای شاخص برای زیرمجموعهای از تصاویر آموزشی بهبود میبخشد.
عملکرد
برای بهبود عملکرد رمزگذار بدون کاهش دقت یا افزایش لرزش، به طور انتخابی از پیچشهای بدون پد برای کاهش اندازه نقشه ویژگی استفاده کردیم. این به ما کنترل بیشتری بر روی اندازههای نقشه ویژگی نسبت به پیچیدگیهای گامبهگام داد. برای حفظ باقیمانده، نقشه ویژگی را قبل از اضافه کردن آن به خروجی یک پیچش بدون پد، برش می دهیم. علاوه بر این، برای استفاده کارآمد از حافظه با مجموعههای دستورالعمل برداری مانند AVX و Neon FP8، عمق نقشههای ویژگی را مضرب 16 قرار دادیم و در نتیجه عملکرد 1.5 برابری را افزایش دادیم.
مدل نهایی ما 1.1 میلیون پارامتر دارد و برای اجرا به 28.1 میلیون ضرب انباشته نیاز دارد. برای مرجع، وانیل Mobilenet V2 (که معماری ما بر اساس آن است) برای اجرا به 300 میلیون ضرب-انباشت نیاز دارد. ما استفاده می کنیم NCNN چارچوب برای استنتاج مدل روی دستگاه و زمان اجرای تک رشته ای (از جمله تشخیص چهره) برای یک فریم از ویدیو در جدول زیر فهرست شده است. لطفاً توجه داشته باشید که زمان اجرای 16 میلیثانیه از پردازش 60 فریم در ثانیه (FPS) پشتیبانی میکند.
![]()
بعدی چیست؟
خط لوله داده های مصنوعی ما به ما این امکان را داد که به طور مکرر بیان و استحکام مدل آموزش دیده را بهبود ببخشیم. ما توالی های مصنوعی را برای بهبود پاسخگویی به عبارات از دست رفته، و همچنین تمرین متعادل بین هویت های مختلف صورت اضافه کردیم. به دلیل فرمول بندی زمانی معماری و تلفات، ستون فقرات بهینه سازی شده با دقت، و حقیقت بدون خطا از داده های مصنوعی، ما به انیمیشن با کیفیت بالا با حداقل محاسبات دست پیدا می کنیم. فیلتر زمانی انجام شده در زیرشبکه وزن FACS به ما امکان می دهد تعداد و اندازه لایه های ستون فقرات را بدون افزایش لرزش کاهش دهیم. از دست دادن سازگاری بدون نظارت به ما امکان می دهد با مجموعه بزرگی از داده های واقعی تمرین کنیم و تعمیم و استحکام مدل خود را بهبود ببخشیم. ما همچنان به کار بر روی اصلاح و بهبود مدلهای خود ادامه میدهیم تا نتایج واضحتر، بدون لرزش و قویتر به دست آوریم.
اگر علاقه مند به کار بر روی چالش های مشابه در خط مقدم ردیابی چهره و یادگیری ماشینی در زمان واقعی هستید، لطفاً برخی از ما را بررسی کنید. موقعیت های باز با تیم ما
پست انیمیشن چهره در زمان واقعی برای آواتارها به نظر می رسد برای اولین بار در وبلاگ Roblox.
- "
- 3d
- دقیق
- در میان
- عمل
- الگوریتم
- الگوریتم
- معرفی
- متحرک سازی
- انیمیشن
- برنامه های کاربردی
- معماری
- هنرمند
- هنرمندان
- بطور خودکار
- نماد
- میانگین
- قبل از
- بهترین
- بلاگ
- جعبه
- مورد
- موارد
- به چالش
- چالش ها
- به چالش کشیدن
- برنامه نویسی
- تجاری
- کامپیوتر
- بینایی کامپیوتر
- ادامه دادن
- خالق
- بحرانی
- محصول
- داده ها
- یادگیری عمیق
- با وجود
- کشف
- توسعه دهندگان
- دستگاه ها
- مختلف
- موثر
- مورد تأیید
- چهره
- چهره ها
- FAST
- ویژگی
- امکانات
- نام خانوادگی
- FPS
- چارچوب
- رایگان
- بیشتر
- آینده
- GIF
- HTTPS
- اندیشه
- تصویر
- پیاده سازی
- بهبود
- از جمله
- افزایش
- IT
- برچسب ها
- بزرگ
- یاد گرفتن
- آموخته
- یادگیری
- محدود شده
- محل
- دستگاه
- فراگیری ماشین
- باعث می شود
- ساخت
- نقشه
- نقشه ها
- مارس
- متاوررس
- میلیون
- مدل
- مدل
- بیش
- گاز نئون
- شبکه
- بینی
- باز کن
- باز می شود
- فرصت ها
- بهینه
- گزینه
- اصلی
- کارایی
- پیش بینی
- زمان واقعی
- كاهش دادن
- کاهش
- نیاز
- تحقیق
- نتایج
- اسباب
- Roblox
- در حال اجرا
- s
- حساس
- تنظیم
- به اشتراک گذاشته شده
- اندازه
- حل
- فضایی
- صحنه
- شروع
- متعاقب
- پشتیبانی
- سیستم
- هدف
- فنی
- La
- متاورس
- از طریق
- زمان
- طرف
- پیگردی
- آموزش
- us
- کاربران
- VeloCity
- تصویری
- فیلم های
- مجازی
- دید
- ویکیپدیا
- مهاجرت کاری
- کارگر
- سال