Roblox از 28 اکتبر شروع و در 31 اکتبر به طور کامل حل شد، یک قطعی 73 ساعته را تجربه کرد.¹ پنجاه میلیون بازیکن به طور منظم هر روز از Roblox استفاده می کنند و برای ایجاد تجربه ای که بازیکنان ما انتظار دارند، مقیاس ما شامل صدها سرویس آنلاین داخلی است. مانند هر سرویس در مقیاس بزرگ، ما هر از چند گاهی با وقفه های خدمات مواجه می شویم، اما طولانی شدن مدت این قطعی آن را به ویژه قابل توجه می کند. ما صمیمانه از جامعه خود بابت این خرابی عذرخواهی می کنیم.
ما این جزئیات فنی را به اشتراک می گذاریم تا جامعه خود را از علت اصلی مشکل، نحوه رسیدگی به آن، و اقداماتی که برای جلوگیری از وقوع مسائل مشابه در آینده انجام می دهیم، درک کند. ما می خواهیم مجدداً تأکید کنیم که در طول این حادثه هیچ گونه از دست دادن اطلاعات کاربر یا دسترسی اشخاص غیرمجاز به هیچ اطلاعاتی وجود نداشته است.
مهندسی Roblox و کارکنان فنی HashiCorp تلاشهای خود را برای بازگرداندن Roblox به خدمت انجام دادند. ما میخواهیم از تیم HashiCorp قدردانی کنیم که منابع خارقالعادهای را به همراه داشت و تا زمانی که مشکلات حل نشد با ما کار کردند.
خلاصه قطعی
قطعی هم از نظر مدت زمان و هم از نظر پیچیدگی منحصر به فرد بود. تیم مجبور شد برای درک علت اصلی و بازگرداندن سرویس، تعدادی چالش را به ترتیب دنبال کند.
- این قطعی 73 ساعت به طول انجامید.
- علت اصلی به دو موضوع مربوط می شود. فعال کردن یک ویژگی پخش جریانی نسبتاً جدید در Consul تحت بار خواندن و نوشتن غیرمعمول بالا منجر به مشاجره بیش از حد و عملکرد ضعیف شد. علاوه بر این، شرایط بار خاص ما باعث ایجاد یک مشکل عملکرد پاتولوژیک در BoltDB شد. سیستم متنباز BoltDB در داخل کنسول برای مدیریت گزارشهای پیشنویس برای انتخاب رهبر و تکرار دادهها استفاده میشود.
- یک خوشه کنسول واحد که از بارهای کاری متعدد پشتیبانی می کند، تأثیر این مسائل را تشدید می کند.
- چالشهای موجود در تشخیص این دو موضوع عمدتاً نامرتبط که در اعماق اجرای کنسول مدفون شدهاند، تا حد زیادی عامل طولانیمدت از کار افتادگی بودند.
- سیستمهای نظارتی حیاتی که دید بهتری را در مورد علت قطعی فراهم میکردند، به سیستمهای آسیبدیده مانند کنسول متکی بودند. این ترکیب به شدت روند تریاژ را مختل کرد.
- ما در رویکرد خود برای بالا بردن Roblox از یک حالت کاملاً پایین تر، متفکر و محتاط بودیم که زمان قابل توجهی نیز صرف کرد.
- ما تلاشهای مهندسی را برای بهبود نظارت خود، حذف وابستگیهای دایرهای در پشته مشاهدهپذیری خود و همچنین تسریع فرآیند راهاندازی خود تسریع کردهایم.
- ما در حال تلاش برای انتقال به مناطق و مراکز داده متعدد در دسترس هستیم.
- ما در حال رفع مشکلاتی در کنسول هستیم که علت اصلی این رویداد بود.
مقدمه: محیط خوشه و HashiStack ما
زیرساخت اصلی Roblox در مراکز داده Roblox اجرا می شود. ما سخت افزار خود و همچنین سیستم های محاسباتی، ذخیره سازی و شبکه خود را در بالای آن سخت افزار مستقر و مدیریت می کنیم. مقیاس استقرار ما با بیش از 18,000 سرور و 170,000 کانتینر قابل توجه است.
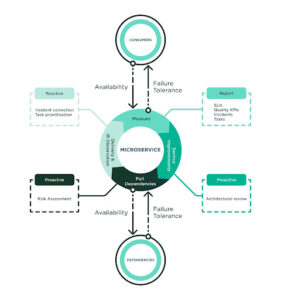
برای اجرای هزاران سرور در چندین سایت، ما از یک مجموعه فناوری که معمولاً به نام "HashiStack" خانه بدوش, کنسول و طاق فناوریهایی هستند که ما برای مدیریت سرورها و سرویسها در سراسر جهان استفاده میکنیم و به ما امکان میدهند تا کانتینرهایی را که از خدمات Roblox پشتیبانی میکنند، هماهنگ کنیم.
خانه بدوش برای برنامه ریزی کار استفاده می شود. این تصمیم میگیرد که کدام کانتینرها روی کدام گرهها و در کدام پورتها قابل دسترسی هستند. همچنین سلامت ظروف را تأیید می کند. همه این داده ها به یک سرویس رجیستری منتقل می شود که پایگاه داده ای از ترکیبات IP:Port است. سرویسهای Roblox از رجیستری خدمات برای یافتن یکدیگر استفاده میکنند تا بتوانند ارتباط برقرار کنند. این فرآیند "کشف خدمات" نامیده می شود. ما استفاده می کنیم کنسول برای کشف خدمات، بررسی های بهداشتی، قفل کردن جلسه (برای سیستم های HA ساخته شده در بالا)، و به عنوان یک فروشگاه KV.
کنسول به عنوان مجموعه ای از ماشین ها در دو نقش مستقر شده است. "رای دهندگان" (5 ماشین) به طور مقتدرانه وضعیت خوشه را حفظ می کنند. "غیر رای دهندگان" (5 ماشین اضافی) کپی های فقط خواندنی هستند که به مقیاس بندی درخواست های خواندن کمک می کنند. در هر زمان، یکی از رای دهندگان توسط خوشه به عنوان رهبر انتخاب می شود. رهبر مسئول تکثیر داده ها برای رأی دهندگان دیگر و تعیین اینکه آیا داده های نوشته شده به طور کامل متعهد شده اند یا خیر. کنسول از الگوریتمی به نام استفاده می کند قایق برای انتخاب رهبر و برای توزیع حالت در سراسر خوشه به گونه ای که اطمینان حاصل شود که هر گره در خوشه با به روز رسانی ها موافقت می کند. این غیر معمول نیست که رهبر از طریق انتخاب رهبر چندین بار در یک روز معین تغییر کند.
تصویر زیر یک اسکرین شات اخیر از داشبورد کنسول در Roblox پس از این حادثه است. بسیاری از معیارهای عملیاتی کلیدی اشاره شده در این پست وبلاگ در سطوح عادی نشان داده شده اند. برای مثال زمان اعمال KV در کمتر از 300 میلیثانیه نرمال در نظر گرفته میشود و در این لحظه 30.6 میلیثانیه است. رهبر کنسول با سرورهای دیگر در خوشه در 32 میلیثانیه گذشته تماس داشته است که بسیار اخیر است.
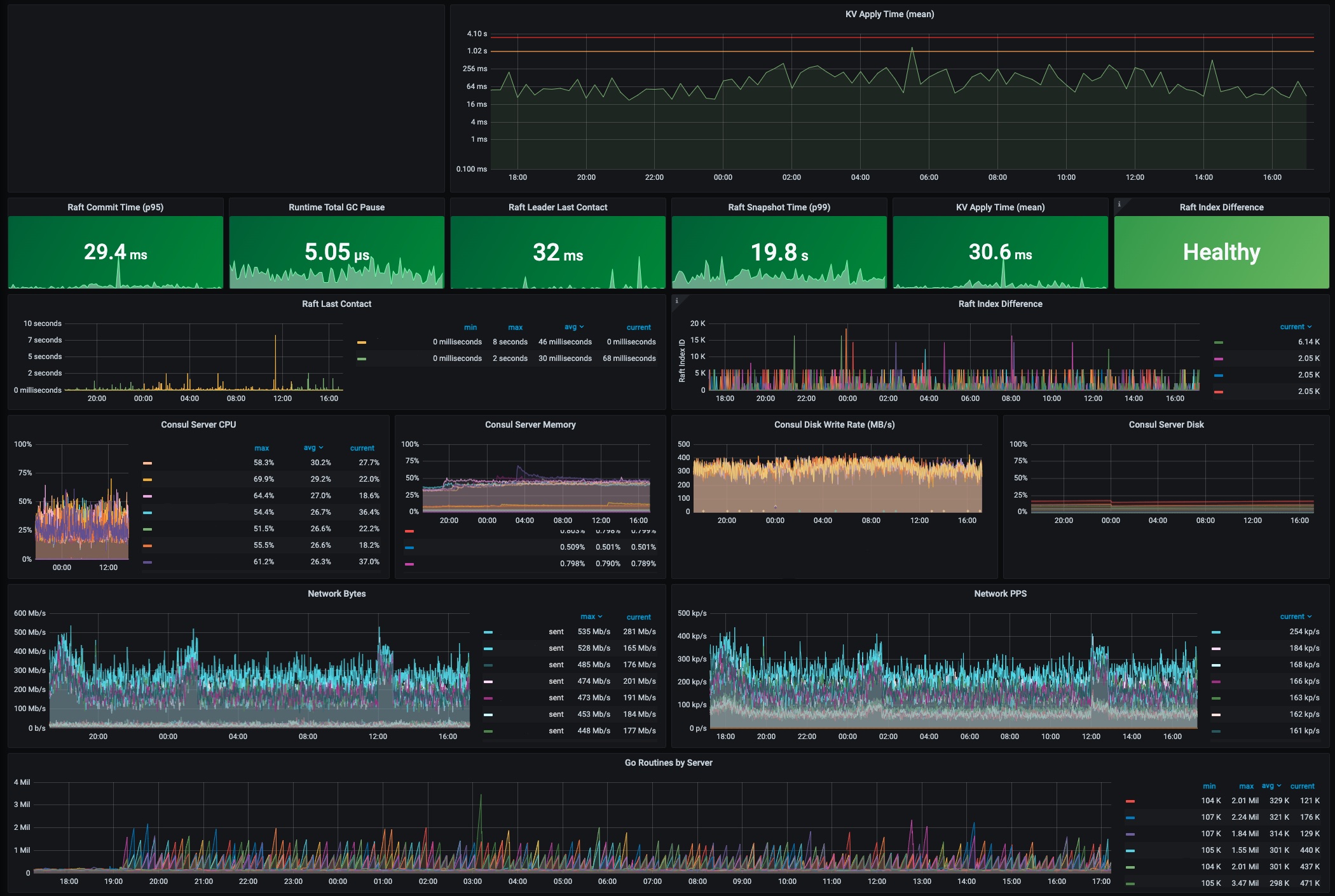
1. عملیات عادی کنسول در Roblox
در ماههای منتهی به حادثه اکتبر، Roblox از کنسول 1.9 به ارتقا یافت کنسول 1.10 بهره بردن از یک ویژگی جدید استریم. این ویژگی استریم برای کاهش چشمگیر CPU و پهنای باند شبکه مورد نیاز برای توزیع بهروزرسانیها در کلاسترهای مقیاس بزرگ مانند آنچه در Roblox است، طراحی شده است.
تشخیص اولیه (10/28 13:37)
در بعد از ظهر 28 اکتبر، Vعملکرد ault تنزل یافته بود و یک سرور Consul دارای بار CPU بالایی بودد مهندسان Roblox شروع به بررسی کردند. در این مرحله بازیکنان تحت تأثیر قرار نگرفتند.
تریاژ اولیه (10/28 13:37 - 10/29 02:00)
تحقیقات اولیه نشان داد که مجموعه کنسولی که Vault و بسیاری از خدمات دیگر به آن وابسته هستند، ناسالم بود. به طور خاص، معیارهای کلاستر Consul تأخیر نوشتن بالا را برای ذخیره KV اساسی که در آن Consul دادهها را ذخیره میکند، نشان داد. تأخیر صدک 50 در این عملیات معمولاً کمتر از 300 میلی ثانیه بود اما اکنون 2 ثانیه بود. مشکلات سخت افزاری در مقیاس Roblox غیرعادی نیست و کنسول می تواند از شکست سخت افزاری جان سالم به در ببرد. با این حال، اگر سختافزار فقط کند باشد و نه از کار بیفتد، میتواند بر عملکرد کلی کنسول تأثیر بگذارد. در این مورد، تیم به عنوان دلیل اصلی به عملکرد ضعیف سخت افزار مشکوک شد و فرآیند جایگزینی یکی از گره های کلاستر Consul را آغاز کرد. این اولین تلاش ما برای تشخیص حادثه بود. تقریباً در این زمان، کارکنان HashiCorp به مهندسان Roblox پیوستند تا در تشخیص و اصلاح کمک کنند. تمام ارجاعات به "تیم" و "تیم مهندسی" از این نقطه به بعد به کارکنان Roblox و HashiCorp اشاره دارد.
حتی با وجود سختافزار جدید، عملکرد خوشه کنسول همچنان دچار مشکل شد. در ساعت 16:35 تعداد بازیکنان آنلاین به 50 درصد عادی کاهش یافت.
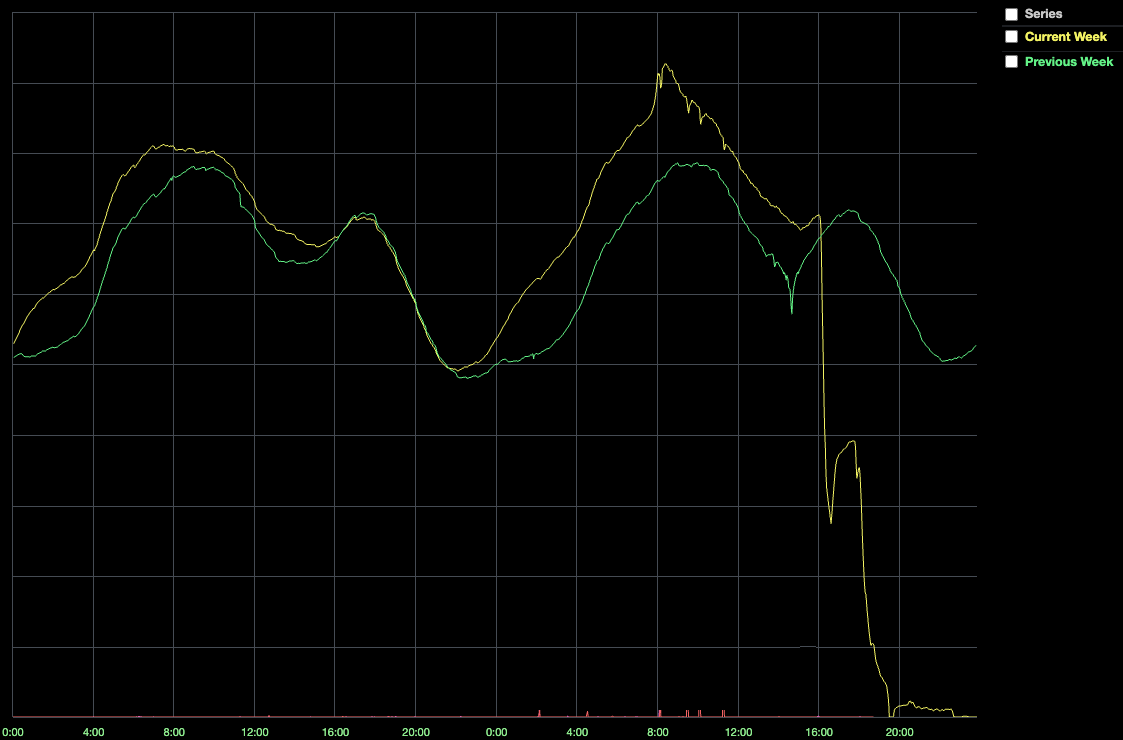
2. CCU در ساعت 16:35 PST Player Drop
این کاهش همزمان با کاهش قابل توجهی در سلامت سیستم بود که در نهایت منجر به قطع کامل سیستم شد. چرا؟ هنگامی که یک سرویس Roblox می خواهد با سرویس دیگری صحبت کند، به کنسول متکی است تا اطلاعات به روزی از مکان سرویسی که می خواهد با آن صحبت کند داشته باشد. با این حال، اگر کنسول ناسالم باشد، سرورها برای اتصال مشکل دارند. علاوه بر این، Nomad و Vault به کنسول متکی هستند، بنابراین وقتی کنسول ناسالم است، سیستم نمی تواند کانتینرهای جدید را برنامه ریزی کند یا اسرار تولید مورد استفاده برای احراز هویت را بازیابی کند. به طور خلاصه، سیستم شکست خورد زیرا کنسول یک نقطه شکست بود و کنسول سالم نبود.
در این مرحله، تیم تئوری جدیدی در مورد اینکه چه چیزی اشتباه میشود ایجاد کرد: افزایش ترافیک. شاید کنسول کند بود زیرا سیستم ما به نقطه اوج رسیده بود و سرورهایی که کنسول در حال اجرا بودند دیگر نمی توانستند بار را تحمل کنند؟ این دومین تلاش ما برای تشخیص علت اصلی حادثه بود.
با توجه به شدت حادثه، تیم تصمیم گرفت که تمام گرههای کلاستر کنسول را با ماشینهای جدید و قدرتمندتر جایگزین کند. این ماشینهای جدید دارای 128 هسته (افزایش 2 برابری) و دیسکهای SSD NVME جدیدتر و سریعتر بودند. تا ساعت 19:00، تیم بیشتر خوشه را به ماشینهای جدید منتقل کرد، اما خوشه هنوز سالم نبود. خوشه گزارش میدهد که اکثر گرهها قادر به همگام شدن با نوشتن نیستند، و تأخیر صدک 50 در نوشتن KV هنوز حدود 2 ثانیه به جای 300 میلیثانیه یا کمتر است.
بازگشت به سرویس تلاش شماره 1 (10/29 02:00 - 04:00)
دو تلاش اول برای بازگرداندن خوشه کنسول به وضعیت سالم ناموفق بود. ما هنوز هم میتوانستیم تاخیر در نوشتن KV بالا و همچنین یک علامت غیرقابل توضیح جدید را ببینیم که نمیتوانیم توضیح دهیم: رهبر کنسول مرتباً با رایدهندگان دیگر هماهنگ نبود.
تیم تصمیم گرفت کل خوشه کنسول را خاموش کند و با استفاده از یک عکس فوری از چند ساعت قبل - شروع قطع، وضعیت آن را بازنشانی کند. ما فهمیدیم که این امر به طور بالقوه باعث از دست رفتن اطلاعات پیکربندی سیستم می شود (نه از دست دادن اطلاعات کاربر). با توجه به شدت قطع و اطمینان ما که میتوانیم دادههای پیکربندی سیستم را در صورت نیاز به صورت دستی بازیابی کنیم، احساس کردیم که این قابل قبول است.
ما انتظار داشتیم که بازیابی از یک عکس فوری گرفته شده در زمانی که سیستم سالم بود، خوشه را به وضعیت سالمی برساند، اما یک نگرانی اضافی داشتیم. حتی با وجود اینکه Roblox در این مرحله هیچ ترافیک تولید شده توسط کاربر در سیستم جریان نداشت، خدمات داخلی Roblox همچنان فعال بودند و با وظیفهشناسی به کنسول دسترسی پیدا میکردند. مکان وابستگی هایشان را بیاموزند و اطلاعات سلامتی خود را به روز کنند. این خواندن و نوشتن بار قابل توجهی بر روی خوشه ایجاد می کرد. ما نگران بودیم که این بار ممکن است بلافاصله خوشه را به حالت ناسالم برگرداند، حتی اگر بازنشانی خوشه با موفقیت انجام شود. برای رفع این نگرانی، پیکربندی کردیم از iptables در خوشه برای مسدود کردن دسترسی. این به ما این امکان را میدهد تا خوشه را به روشی کنترلشده پشتیبانسازی کنیم و به ما کمک کند بفهمیم آیا باری که مستقل از ترافیک کاربر بر روی کنسول وارد میکنیم بخشی از مشکل است یا خیر.
تنظیم مجدد به آرامی انجام شد و در ابتدا معیارها خوب به نظر می رسید. زمانی که ما آن را حذف کردیم از iptables بلوک، کشف سرویس و بار بررسی سلامت از سرویس های داخلی همانطور که انتظار می رفت بازگشت. با این حال، عملکرد کنسول دوباره شروع به تنزل کرد، و در نهایت به همان جایی که شروع کردیم بازگشتیم: صدک 50 در عملیات نوشتن KV در 2 ثانیه بازگشت. خدماتی که به کنسول وابسته بودند شروع به علامت گذاری "ناسالم" می کردند و در نهایت، سیستم به وضعیت مشکل ساز که اکنون آشنا بود، بازگشت. الان ساعت 04:00 بود. به وضوح چیزی در مورد بار ما روی کنسول وجود داشت که باعث ایجاد مشکل می شد، و پس از گذشت 14 ساعت از حادثه، ما هنوز نمی دانستیم آن چیست.
بازگشت به سرویس تلاش شماره 2 (10/29 04:00 - 10/30 02:00)
ما شکست سخت افزاری را رد کرده بودیم. سخت افزار سریعتر کمکی نکرده بود و همانطور که بعداً فهمیدیم، به طور بالقوه به ثبات آسیب می رساند. تنظیم مجدد وضعیت داخلی کنسول نیز کمکی نکرده بود. هیچ ترافیک کاربری وجود نداشت، اما کنسول همچنان کند بود. ما اهرم کرده بودیم از iptables اجازه دهید ترافیک به آرامی به خوشه بازگردد. آیا این خوشه به سادگی به دلیل حجم عظیم هزاران کانتینر که سعی در اتصال مجدد داشتند به حالت ناسالم بازگردانده می شد؟ این سومین تلاش ما برای تشخیص علت اصلی حادثه بود.
تیم مهندسی تصمیم گرفت که استفاده از کنسول را کاهش دهد و سپس با دقت و سیستماتیک آن را مجدداً معرفی کند. برای اطمینان از اینکه نقطه شروع تمیزی داریم، ترافیک خارجی باقیمانده را نیز مسدود کردیم. ما فهرست کاملی از خدماتی که از Consul استفاده میکنند جمعآوری کردیم و تغییرات پیکربندی را برای غیرفعال کردن تمام استفادههای غیرضروری انجام دادیم. این فرآیند به دلیل تنوع گسترده سیستم ها و انواع تغییر پیکربندی مورد نظر، چندین ساعت طول کشید. سرویسهای Roblox که معمولاً صدها نمونه در حال اجرا بودند به تک رقمی کاهش یافتند. فرکانس بررسی سلامت از 60 ثانیه به 10 دقیقه کاهش یافت تا به خوشه اتاق تنفس اضافی داده شود. در ساعت 16:00 روز 29 اکتبر، بیش از 24 ساعت پس از شروع قطعی، تیم دومین تلاش خود را برای بازگرداندن Roblox آنلاین آغاز کرد. بار دیگر، مرحله اولیه این تلاش مجدد خوب به نظر می رسید، اما تا ساعت 02:00 30 اکتبر، کنسول دوباره در وضعیت ناسالم قرار گرفت، این بار با بار قابل توجهی کمتر از خدمات Roblox که به آن وابسته هستند.
در این مرحله، واضح بود که استفاده کلی کنسول تنها عامل مؤثر در کاهش عملکرد نبود که برای اولین بار در 28 ام متوجه شدیم. با توجه به این درک، تیم دوباره چرخید. به جای نگاه کردن به کنسول از دیدگاه خدمات Roblox که به آن وابسته است، تیم شروع به بررسی اطلاعات داخلی کنسول برای سرنخ کرد.
تحقیق در مورد بحث (10/30 02:00 - 10/30 12:00)
در طی 10 ساعت آینده، تیم مهندسی به بررسی عمیقتر گزارشهای اشکالزدایی و معیارهای سطح سیستم عامل پرداختند. این داده ها نشان می دهد که Consul KV می نویسد برای مدت طولانی مسدود می شود. به عبارت دیگر، "مشاهده". علت این مشاجره بلافاصله مشخص نبود، اما یک نظریه این بود که تغییر سرورهای اصلی CPU از 64 به 128 در اوایل قطع ممکن است مشکل را بدتر کند. پس از بررسی داده های htop و داده های اشکال زدایی عملکرد نشان داده شده در تصاویر زیر، تیم به این نتیجه رسید که ارزش بازگشت به 64 سرور اصلی مشابه سرورهای قبل از قطع شدن را دارد. تیم شروع به آمادهسازی سختافزار کرد: کنسول نصب شد، پیکربندیهای سیستمعامل سهبار بررسی شد، و ماشینها با جزئیات تا حد امکان برای سرویس آماده شدند. سپس تیم، کلاستر Consul را به 64 سرور CPU Core برگرداند، اما این تغییر کمکی نکرد. این چهارمین تلاش ما برای تشخیص علت اصلی حادثه بود.
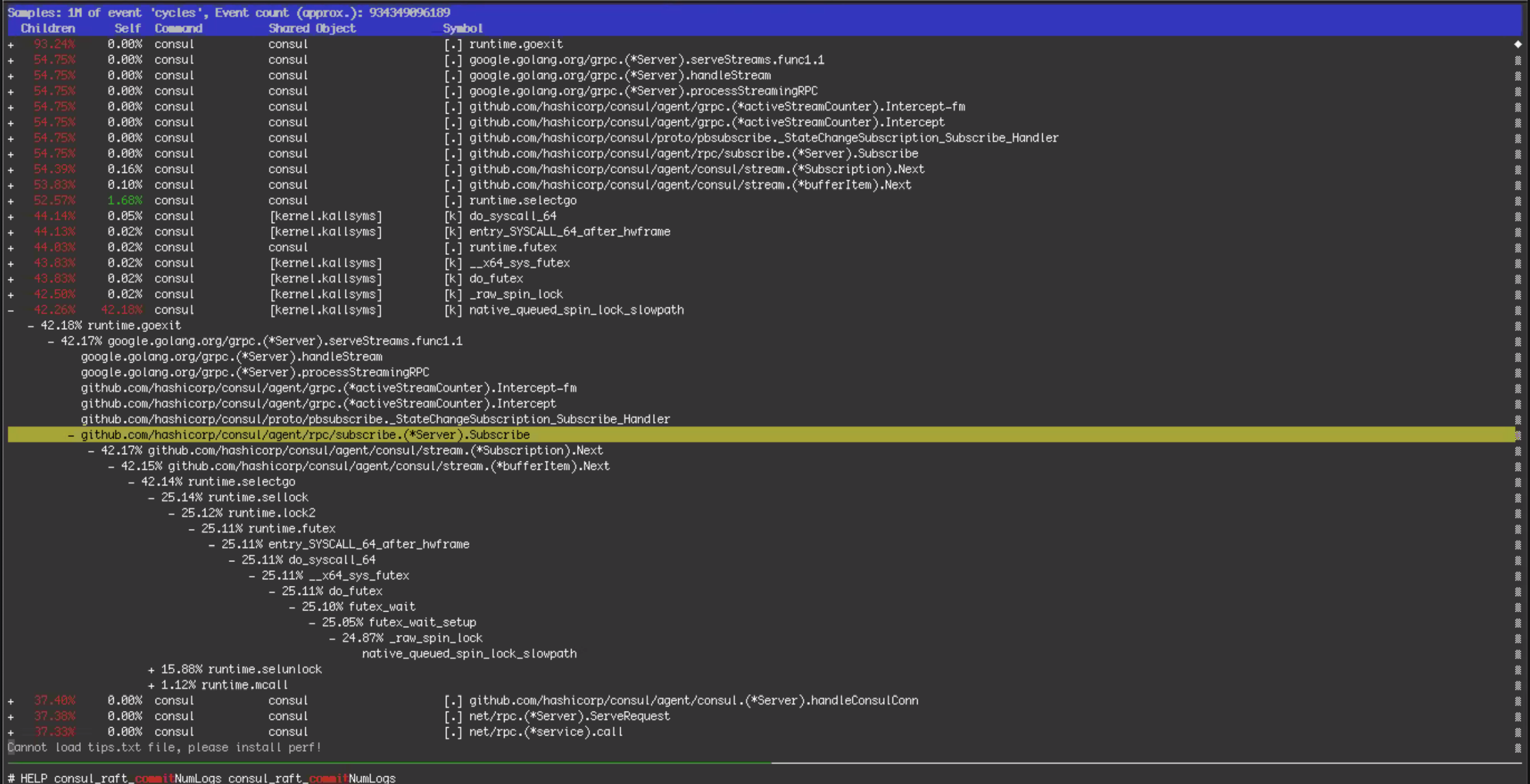
3. سپس این را با یک گزارش perf همانطور که در بالا نشان داده شده است نمایش دادیم. بیشتر زمان در قفلهای اسپین هسته از طریق مسیر کد اشتراک Streaming سپری شد.
4. HTOP استفاده از CPU را در 128 هسته نشان می دهد.
علل ریشه ای یافت شده (10/30 12:00 - 10/30 20:00)
چندین ماه پیش، ما یک ویژگی جدید استریم Consul را در زیرمجموعه ای از خدمات خود فعال کردیم. این ویژگی که برای کاهش استفاده از CPU و پهنای باند شبکه خوشه Consul طراحی شده بود، همانطور که انتظار می رفت کار کرد، بنابراین در چند ماه آینده ما به صورت تدریجی این ویژگی را در بسیاری از خدمات باطن خود فعال کردیم. در تاریخ 27 اکتبر ساعت 14:00، یک روز قبل از قطع، ما این ویژگی را در یک سرویس پشتیبان که وظیفه مسیریابی ترافیک را بر عهده دارد، فعال کردیم. به عنوان بخشی از این عرضه، به منظور آماده شدن برای افزایش ترافیکی که معمولاً در پایان سال شاهد آن هستیم، تعداد گرههایی را که از مسیریابی ترافیک پشتیبانی میکنند تا 50 درصد افزایش دادیم. این سیستم یک روز قبل از شروع حادثه با پخش در این سطح به خوبی کار می کرد، بنابراین در ابتدا مشخص نبود که چرا عملکرد آن تغییر کرده است. با این حال، از طریق تجزیه و تحلیل گزارشهای perf و نمودارهای شعله از سرورهای Consul، شاهد شواهدی از مسیرهای کد جریانی بودیم که مسئول این مشاجره هستند که باعث استفاده بالای CPU میشوند. ما ویژگی پخش جریانی را برای همه سیستمهای کنسول، از جمله گرههای مسیریابی ترافیک، غیرفعال کردیم. تغییر پیکربندی در ساعت 15:51 به پایان رسید، در این زمان صدک 50 برای نوشتن Consul KV به 300 میلیثانیه کاهش یافت. بالاخره به پیشرفتی دست یافتیم.
چرا پخش جریانی مشکل داشت؟ HashiCorp توضیح داد که در حالی که استریمینگ به طور کلی کارآمدتر بود، از عناصر کنترل همزمان (کانالهای Go) کمتری نسبت به نظرسنجی طولانی استفاده کرد. تحت بار بسیار بالا - به ویژه، هم بار خواندن بسیار بالا و هم بار نوشتن بسیار بالا - طراحی جریان میزان اختلاف را در یک کانال Go تشدید می کند، که باعث مسدود شدن در هنگام نوشتن می شود و کارایی آن را به میزان قابل توجهی کاهش می دهد. این رفتار همچنین تأثیر سرورهای با تعداد هسته بالاتر را توضیح داد: آن سرورها معماریهای سوکت دوگانه با مدل حافظه NUMA بودند. بنابراین بحث اضافی در مورد منابع مشترک در این معماری بدتر شد. با خاموش کردن پخش جریانی، سلامت خوشه کنسول را به طرز چشمگیری بهبود بخشیم.
با وجود موفقیت، ما هنوز از جنگل خارج نشده بودیم. ما شاهد بودیم که کنسول بهطور متناوب رهبران خوشهای جدید را انتخاب میکرد، که طبیعی بود، اما همچنین شاهد بودیم که برخی از رهبران همان مشکلات تأخیر را نشان میدهند که قبل از غیرفعال کردن پخش جریانی مشاهده میکردیم، که طبیعی نبود. بدون هیچ سرنخ آشکاری که به علت اصلی مشکل رهبر کند اشاره کند، و با شواهدی مبنی بر سالم بودن خوشه تا زمانی که سرورهای خاصی به عنوان رهبر انتخاب نشده اند، تیم تصمیم عملی را اتخاذ کرد تا با جلوگیری از بروز مشکل، مشکل را حل کند. رهبران از انتخاب ماندن این تیم را قادر ساخت تا روی بازگرداندن خدمات Roblox که به کنسول متکی هستند به وضعیت سالم تمرکز کنند.
اما در مورد رهبران کند چه می گذشت؟ ما در طول این حادثه متوجه این موضوع نشدیم، اما مهندسان HashiCorp علت اصلی را در روزهای پس از قطعی مشخص کردند. Consul از یک کتابخانه پایدار منبع باز معروف به نام BoltDB برای ذخیره لاگ های Raft استفاده می کند. این است نه برای ذخیره وضعیت فعلی در کنسول استفاده می شود، بلکه یک گزارش عملیاتی در حال اعمال است. برای جلوگیری از رشد نامحدود BoltDB، کنسول به طور مرتب عکس های فوری را انجام می دهد. عملیات Snapshot وضعیت فعلی کنسول را روی دیسک می نویسد و سپس قدیمی ترین ورودی های گزارش را از BoltDB حذف می کند.
با این حال، به دلیل طراحی BoltDB، حتی زمانی که قدیمیترین ورودیهای گزارش حذف میشوند، فضای استفاده شده از BoltDB روی دیسک هرگز کوچک نمیشود. در عوض، تمام صفحات (قطعات 4 کیلوبایتی در فایل) که برای ذخیره داده های حذف شده استفاده می شدند، به عنوان "رایگان" علامت گذاری می شوند و برای نوشتن های بعدی مجددا استفاده می شوند. BoltDB این صفحات رایگان را در ساختاری به نام "لیست آزاد" آن ردیابی می کند. به طور معمول، تأخیر نوشتن به طور معناداری تحت تأثیر زمان لازم برای به روز رسانی لیست آزاد نیست، بلکه حجم کاری Roblox یک مشکل عملکرد پاتولوژیک در BoltDB را نشان داد که نگهداری از لیست آزاد را بسیار گران می کرد.
بازیابی سرویس حافظه پنهان (10/30 20:00 - 10/31 05:00)
54 ساعت از شروع قطع برق گذشته بود. با غیرفعال شدن جریان و فرآیندی برای جلوگیری از انتخاب رهبران کند، کنسول اکنون به طور مداوم پایدار بود. تیم آماده تمرکز بر بازگشت به خدمت بود.
Roblox از یک الگوی microservices معمولی برای backend خود استفاده می کند. در پایین "پشته" میکروسرویس ها پایگاه داده ها و حافظه های پنهان قرار دارند. این پایگاههای اطلاعاتی تحت تأثیر قطعی قرار نگرفتند، اما سیستم ذخیرهسازی که به طور منظم 1B درخواست در ثانیه در لایههای متعدد خود در طول عملیات منظم سیستم رسیدگی میکند، ناسالم بود. از آنجایی که حافظه پنهان ما دادههای گذرا را ذخیره میکند که به راحتی میتوانند از پایگاههای داده زیربنایی دوباره پر شوند، سادهترین راه برای بازگرداندن سیستم ذخیرهسازی به حالت سالم، استقرار مجدد آن بود.
فرآیند استقرار مجدد حافظه پنهان با یک سری مسائل روبرو شد:
- احتمالاً به دلیل بازنشانی عکس فوری خوشه کنسول که قبلاً در آن انجام شده بود، دادههای زمانبندی داخلی که سیستم حافظه پنهان در Consul KV ذخیره میکند نادرست بوده است.
- استقرار کش های کوچک بیشتر از حد انتظار طول کشید و استقرار کش های بزرگ به پایان نرسید. معلوم شد که یک گره ناسالم وجود دارد که زمانبندی کار آن را کاملاً باز میداند تا ناسالم. این منجر به تلاش زمانبندی کار برای برنامهریزی شدید کارهای کش در این گره شد که به دلیل ناسالم بودن گره شکست خورد.
- ابزار استقرار خودکار سیستم حافظه پنهان برای پشتیبانی از تنظیمات افزایشی برای استقرار در مقیاس بزرگ ساخته شده است که قبلاً ترافیک را در مقیاس مدیریت میکردند، نه تلاشهای تکراری برای راهاندازی یک خوشه بزرگ از ابتدا.
تیم در طول شب برای شناسایی و رسیدگی به این مسائل، اطمینان از استقرار صحیح سیستمهای حافظه پنهان و تأیید صحت کار کرد. در ساعت 05:00 31 اکتبر، 61 ساعت از شروع قطع، ما یک کلاستر کنسول سالم و یک سیستم ذخیره سازی سالم داشتیم. ما آماده بودیم تا بقیه Roblox را مطرح کنیم.
بازگشت بازیکنان (10/31 05:00 – 10/31 16:00)
مرحله نهایی بازگشت به خدمت به طور رسمی از ساعت 05:00 روز 31 آغاز شد. مشابه سیستم کش، بخش قابل توجهی از سرویس های در حال اجرا در طول قطع اولیه یا مراحل عیب یابی خاموش شده بودند. تیم باید این سرویسها را در سطوح ظرفیت صحیح مجدداً راهاندازی میکرد و تأیید میکرد که درست کار میکنند. این به آرامی پیش رفت و تا ساعت 10:00 ما آماده بودیم تا به روی بازیکنان باز شویم.
با وجود حافظه های سرد و سیستمی که هنوز در مورد آن نامطمئن بودیم، نمی خواستیم سیل ترافیکی که به طور بالقوه می تواند سیستم را به حالت ناپایدار بازگرداند. برای جلوگیری از سیل، از فرمان DNS برای مدیریت تعداد بازیکنانی که میتوانستند به Roblox دسترسی داشته باشند، استفاده کردیم. این به ما اجازه داد تا درصد معینی از بازیکنانی که بهطور تصادفی انتخاب شدهاند را وارد کنیم، در حالی که بقیه همچنان به صفحه نگهداری ثابت ما هدایت میشوند. هر بار که درصد را افزایش دادیم، بار پایگاه داده، عملکرد حافظه پنهان و پایداری کلی سیستم را بررسی کردیم. کار در طول روز ادامه یافت و دسترسی را تقریباً 10 درصد افزایش داد. ما از اینکه دیدیم برخی از اختصاصیترین بازیکنانمان طرح فرمان DNS ما را کشف کردند و شروع به تبادل این اطلاعات در توییتر کردند، لذت بردیم تا بتوانند با بازگرداندن سرویس، دسترسی «بهموقع» داشته باشند. در ساعت 16:45 یکشنبه، 73 ساعت پس از شروع قطعی، به 100% بازیکنان دسترسی داده شد و Roblox به طور کامل فعال شد.
تجزیه و تحلیل بیشتر و تغییرات ناشی از خاموشی
در حالی که بازیکنان اجازه داشتند در 31 اکتبر به Roblox بازگردند، Roblox و HashiCorp به بهبود درک خود از قطعی در طول هفته بعد ادامه دادند. مسائل مشاجره خاص در پروتکل جریان جدید شناسایی و جدا شد. در حالی که HashiCorp داشت جریان محک در مقیاسی مشابه با استفاده از Roblox، آنها قبلاً این رفتار خاص را مشاهده نکرده بودند، زیرا از ترکیبی از تعداد زیادی جریان و نرخ ریزش بالا آشکار می شد. تیم مهندسی HashiCorp در حال ایجاد معیارهای آزمایشگاهی جدید برای بازتولید موضوع بحث خاص و انجام تستهای مقیاس اضافی است. HashiCorp همچنین در تلاش است تا طراحی سیستم پخش را بهبود بخشد تا از مشاجره تحت فشار شدید جلوگیری کند و عملکرد پایدار در چنین شرایطی را تضمین کند.
تجزیه و تحلیل بیشتر مشکل رهبر کند نیز علت اصلی نوشتن دادههای Raft دو ثانیهای و مسائل مربوط به سازگاری خوشهای را کشف کرد. مهندسان به نمودارهای شعله مانند شکل زیر نگاه کردند تا درک بهتری از عملکرد داخلی BoltDB داشته باشند.
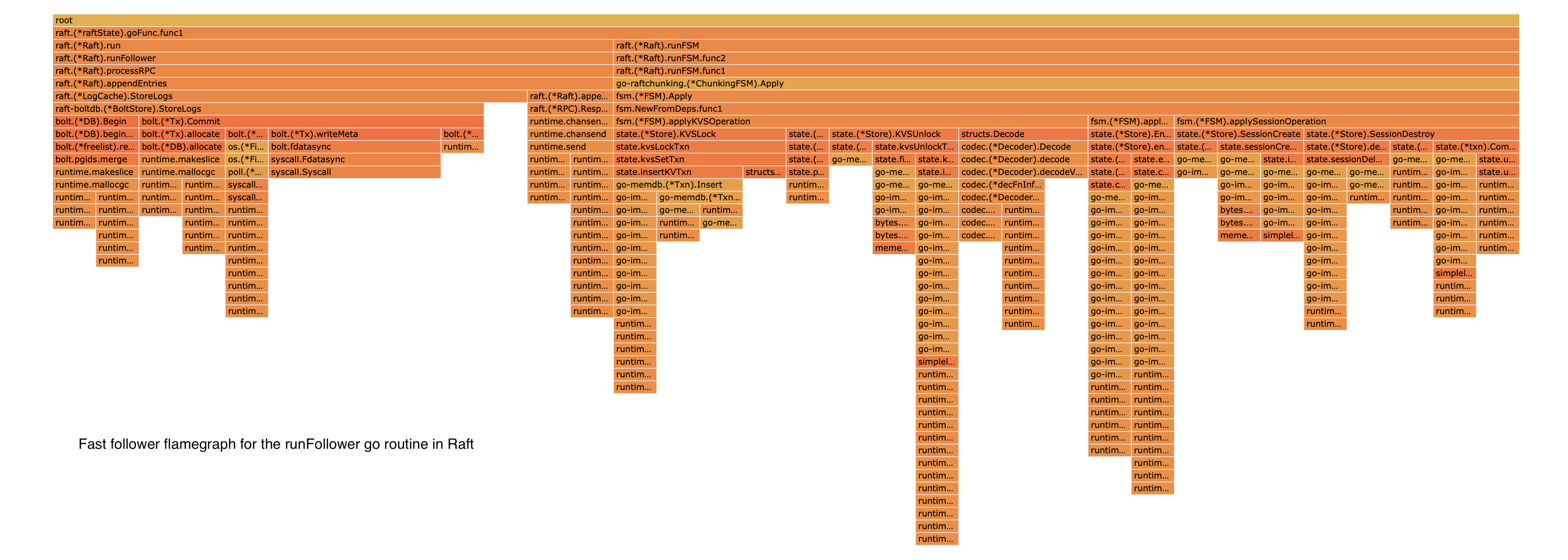
5. تجزیه و تحلیل عملیات فهرست آزاد BoltDB.
همانطور که قبلا ذکر شد، کنسول از یک کتابخانه پایدار به نام BoltDB برای ذخیره داده های گزارش Raft استفاده می کند. با توجه به یک الگوی استفاده خاص ایجاد شده در طول حادثه، عملیات نوشتن 16 کیلوبایت در عوض بسیار بزرگتر می شد. می توانید مشکل را در این اسکرین شات ها مشاهده کنید:
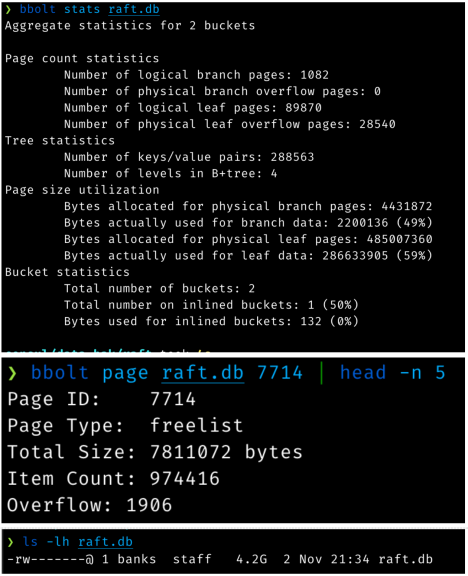
6. آمار دقیق BoldDB مورد استفاده در تجزیه و تحلیل.
خروجی فرمان قبلی چند چیز را به ما می گوید:
- این ذخیرهسازی 4.2 گیگابایتی فقط 489 مگابایت داده واقعی (شامل همه موارد داخلی فهرست) را ذخیره میکند. 3.8 گیگابایت فضای "خالی" است.
- La لیست آزاد 7.8 مگابایت است زیرا حاوی نزدیک به یک میلیون شناسه صفحه رایگان است.
این بدان معناست که به ازای هر لاگ اضافه شده (هر Raft پس از چند بار نوشتن)، یک لیست آزاد 7.8 مگابایتی جدید نیز روی دیسک نوشته میشود، حتی اگر دادههای خام واقعی اضافه شده 16 کیلوبایت یا کمتر باشد.
فشار برگشتی روی این عملیات همچنین بافرهای کامل TCP را ایجاد کرد و به زمان نوشتن ۲ تا ۳ ثانیه روی رهبران ناسالم کمک کرد. تصویر زیر تحقیق در مورد ویندوز TCP Zero را در طول این حادثه نشان می دهد.
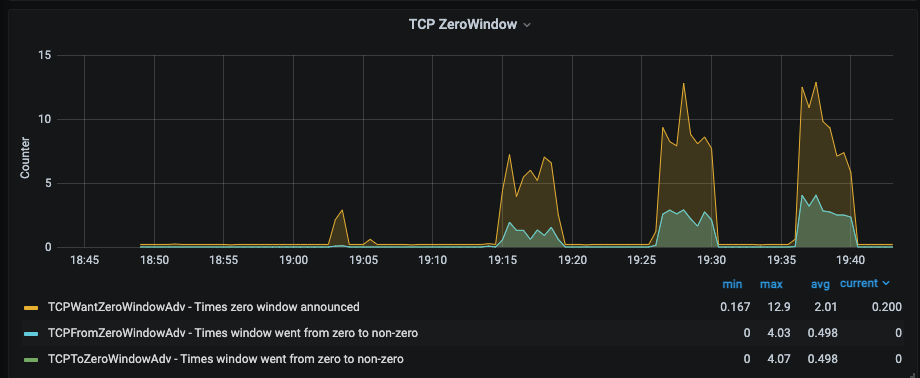
7. در مورد پنجره های TCP صفر تحقیق کنید. هنگامی که بافر گیرنده TCP شروع به پر شدن می کند، می تواند پنجره دریافت خود را کاهش دهد. اگر پر شود، می تواند پنجره را به صفر برساند، که به فرستنده TCP می گوید ارسال را متوقف کند.
HashiCorp و Roblox فرآیندی را با استفاده از ابزار BoltDB موجود برای فشرده سازی پایگاه داده توسعه داده و به کار گرفته اند که مشکلات عملکرد را حل کرده است.
پیشرفت های اخیر و گام های آینده
2.5 ماه از خاموشی می گذرد. چه کار کرده ایم؟ ما از این زمان استفاده کردیم تا تا آنجا که میتوانیم از خاموشی بیاموزیم، اولویتهای مهندسی را بر اساس آموختههایمان تنظیم کنیم، و سیستمهایمان را به شدت سخت کنیم. یکی از ارزشهای Roblox ما احترام به انجمن است، و اگرچه میتوانستیم پستی را زودتر برای توضیح آنچه اتفاق افتاده منتشر کنیم، احساس میکنیم که مدیون شما، جامعه ما هستیم که قبل از انتشار، پیشرفت قابلتوجهی در بهبود قابلیت اطمینان سیستمهایمان داشته باشیم.
لیست کامل بهبودهای قابلیت اطمینان کامل و در حین پرواز برای این نوشتن بسیار طولانی و مفصل است، اما موارد کلیدی در اینجا آمده است:
بهبودهای تله متری
یک وابستگی دایرهای بین سیستمهای تلهمتری ما و کنسول وجود داشت، به این معنی که وقتی کنسول ناسالم بود، ما فاقد دادههای تلهمتری بودیم که تشخیص اشتباه را برای ما آسانتر میکرد. ما این وابستگی دایره ای را حذف کرده ایم. سیستم های تله متری ما دیگر به سیستم هایی که برای نظارت پیکربندی شده اند وابسته نیستند.
ما سیستم های تله متری خود را گسترش داده ایم تا دید بهتری نسبت به عملکرد کنسول و BoltDB فراهم کنیم. اکنون در صورت وجود نشانههایی مبنی بر نزدیک شدن سیستم به وضعیتی که باعث این قطعی شده است، هشدارهای بسیار هدفمند دریافت میکنیم. ما همچنین سیستم های تله متری خود را گسترش داده ایم تا الگوهای ترافیکی بین خدمات Roblox و Consul را بیشتر نمایان کنیم. این دید اضافی به رفتار و عملکرد سیستم ما در سطوح مختلف قبلاً در طول جلسات ارتقاء سیستم و اشکال زدایی به ما کمک کرده است.
گسترش به چندین منطقه در دسترس و مراکز داده
اجرای همه سرویسهای باطن Roblox در یک کلاستر Consul ما را در معرض چنین اختلالی قرار داد. ما قبلاً سرورها و شبکهای را برای یک مرکز داده اضافی و از نظر جغرافیایی متمایز ساختهایم که میزبان خدمات باطن ما خواهد بود. ما تلاش هایی در حال انجام داریم تا به مناطق متعدد در دسترس در این مراکز داده حرکت کنیم. ما تغییرات عمده ای در نقشه راه مهندسی و برنامه های کارکنان خود ایجاد کرده ایم تا این تلاش ها را تسریع کنیم.
کنسول ارتقا و شاردینگ
Roblox هنوز به سرعت در حال رشد است، بنابراین حتی با وجود چندین کلاستر Consul، ما می خواهیم باری را که بر Consul می گذاریم کاهش دهیم. نحوه استفاده سرویسهایمان از فروشگاه KV کنسول و بررسیهای سلامت را بررسی کردهایم، و برخی از خدمات حیاتی را به خوشههای اختصاصی خود تقسیم کردهایم، و بار روی خوشه کنسول مرکزی خود را به سطح ایمنتری کاهش دادهایم.
برخی از خدمات اصلی Roblox از فروشگاه KV Consul به طور مستقیم به عنوان مکانی مناسب برای ذخیره داده ها استفاده می کنند، حتی اگر ما سیستم های ذخیره سازی دیگری داریم که احتمالا مناسب تر هستند. ما در حال انتقال این داده ها به یک سیستم ذخیره سازی مناسب تر هستیم. پس از تکمیل، این کار باعث کاهش بار روی کنسول نیز می شود.
ما مقدار زیادی از داده های KV منسوخ را کشف کردیم. حذف این داده های منسوخ عملکرد کنسول را بهبود بخشید.
ما در حال همکاری نزدیک با HashiCorp برای استقرار نسخه جدیدی از Consul هستیم که جایگزین BoltDB با جانشینی به نام bbolt که با رشد نامحدود آزاد لیست مشکلی ندارد. ما عمداً این تلاش را به سال جدید به تعویق انداختیم تا از ارتقای پیچیده در زمان اوج ترافیک پایان سال خود جلوگیری کنیم. ارتقا در حال حاضر در حال آزمایش است و در Q1 تکمیل خواهد شد.
بهبود رویههای بوت استرپینگ و مدیریت پیکربندی
تلاش برای بازگشت به خدمات توسط تعدادی از عوامل، از جمله استقرار و گرم شدن حافظه پنهان مورد نیاز خدمات Roblox، کند شد. ما در حال توسعه ابزارها و فرآیندهای جدید هستیم تا این فرآیند را خودکارتر و کمتر در معرض خطا قرار دهیم. به ویژه، ما مکانیسمهای استقرار کش خود را دوباره طراحی کردهایم تا اطمینان حاصل کنیم که میتوانیم به سرعت سیستم حافظه پنهان خود را از یک شروع ثابت بالا بیاوریم. اجرای این امر در حال انجام است.
ما با HashiCorp کار کردیم تا چندین پیشرفت Nomad را شناسایی کنیم که یافتن مشاغل بزرگ را پس از مدت طولانی در دسترس نبودن آسانتر میکند. این بهبودها به عنوان بخشی از ارتقاء بعدی Nomad ما که برای اواخر این ماه برنامه ریزی شده است، به کار گرفته می شود.
ما مکانیزمهایی را برای تغییرات سریعتر پیکربندی ماشین توسعه دادهایم.
معرفی مجدد استریمینگ
ما در ابتدا استریم را برای کاهش استفاده از CPU و پهنای باند شبکه کلاستر Consul مستقر کردیم. هنگامی که یک پیاده سازی جدید در مقیاس ما با حجم کاری ما آزمایش شد، انتظار داریم آن را با دقت دوباره به سیستم های خود معرفی کنیم.
یادداشتی در مورد ابر عمومی
پس از قطعی مانند این، طبیعی است که بپرسیم آیا Roblox قصد دارد به ابر عمومی منتقل شود و به شخص ثالث اجازه دهد خدمات اساسی محاسبات، ذخیره سازی و شبکه ما را مدیریت کند.
یکی دیگر از ارزش های Roblox ما Take The Long View است و این مقدار به شدت به تصمیم گیری ما کمک می کند. ما زیرساخت های بنیادی خود را به صورت پیش فرض می سازیم و مدیریت می کنیم، زیرا در مقیاس فعلی و مهمتر از آن، مقیاسی که می دانیم با رشد پلت فرم خود به آن خواهیم رسید، معتقدیم این بهترین راه برای حمایت از کسب و کار و جامعه ما است. به طور خاص، با ساخت و مدیریت مراکز داده خودمان برای خدمات باطنی و لبه شبکه، توانستهایم هزینهها را در مقایسه با ابر عمومی کنترل کنیم. این پس انداز مستقیماً بر مبلغی که ما می توانیم به سازندگان در پلتفرم پرداخت کنیم تأثیر می گذارد. علاوه بر این، داشتن سخت افزار خود و ایجاد زیرساخت های لبه خود به ما امکان می دهد تا تغییرات عملکرد را به حداقل برسانیم و تأخیر بازیکنان خود را در سراسر جهان به دقت مدیریت کنیم. عملکرد ثابت و تأخیر کم برای تجربه بازیکنان ما، که لزوماً در نزدیکی مراکز داده ارائه دهندگان ابر عمومی قرار ندارند، بسیار مهم است.
توجه داشته باشید که ما از نظر ایدئولوژیکی به هیچ رویکرد خاصی وابسته نیستیم: ما از ابر عمومی برای موارد استفاده استفاده میکنیم که در آن برای بازیکنان و توسعهدهندگان ما منطقیتر است. به عنوان مثال، ما از ابر عمومی برای ظرفیت انفجاری، بخشهای بزرگی از گردشهای کاری DevOps و بیشتر تحلیلهای داخلی خود استفاده میکنیم. به طور کلی، ابر عمومی ابزار خوبی برای برنامههایی است که عملکرد و تأخیر حیاتی ندارند و در مقیاس محدود اجرا میشوند. با این حال، برای بیشترین عملکرد و بارهای کاری حیاتی تأخیر، ما انتخاب کردهایم که زیرساختهای خودمان را به صورت اولیه بسازیم و مدیریت کنیم. ما این انتخاب را انجام دادیم که میدانستیم زمان، پول و استعداد میطلبد، اما همچنین میدانستیم که به ما امکان میدهد پلتفرم بهتری بسازیم. این با مقدار Take The Long View ما مطابقت دارد.
پایداری سیستم از زمان قطع
Roblox معمولاً در پایان دسامبر یک موج ترافیک دریافت می کند. ما کارهای قابل اعتماد بیشتری برای انجام داریم، اما خوشحالیم که گزارش دهیم Roblox حتی یک حادثه تولید قابل توجه در طول موج دسامبر نداشته است، و عملکرد و پایداری Consul و Nomad در طول این افزایش بسیار عالی بود. به نظر می رسد که پیشرفت های فوری قابلیت اطمینان ما در حال حاضر نتیجه داده است، و با پایان یافتن پروژه های بلندمدت ما، انتظار نتایج بهتری نیز داریم.
بستن اندیشه
ما می خواهیم از جامعه جهانی Roblox برای درک و حمایت آنها تشکر کنیم. یکی دیگر از ارزش های Roblox ما مسئولیت پذیری است، و ما مسئولیت کامل آنچه را که در اینجا رخ داده است بر عهده می گیریم. مایلیم یک بار دیگر از تیم HashiCorp صمیمانه تشکر کنیم. مهندسان آنها در ابتدای این قطعی بی سابقه به ما کمک کردند و کنار ما را ترک نکردند. حتی در حال حاضر، با وجود چندین هفته خاموشی، مهندسان Roblox و HashiCorp به همکاری نزدیک خود ادامه میدهند تا اطمینان حاصل کنند که ما مجموعاً هر کاری را انجام میدهیم تا از تکرار مجدد قطعی مشابه جلوگیری کنیم.
در نهایت، ما میخواهیم از همکاران Roblox خود برای تأیید اینکه چرا اینجا مکانی شگفتانگیز برای کار است، تشکر کنیم. در Roblox ما به مدنیت و احترام اعتقاد داریم. وقتی همه چیز به خوبی پیش می رود، ساده و محترمانه است، اما آزمون واقعی این است که وقتی شرایط سخت می شود، چگونه با یکدیگر رفتار می کنیم. در یک نقطه از قطعی 73 ساعته، با تیک تاک ساعت و افزایش استرس، تعجب آور نیست که ببینیم کسی خونسردی خود را از دست داده، سخنی توهین آمیز بگوید، یا با صدای بلند تعجب کند که این همه تقصیر کیست. اما این چیزی نیست که اتفاق افتاده است. ما از همدیگر حمایت میکردیم و بهصورت یک تیم شبانهروز با هم کار میکردیم تا زمانی که سرویس سالم بود. ما البته به این قطع و تأثیری که بر جامعه ما داشت افتخار نمی کنیم، اما ما هستند به این افتخار می کنیم که چگونه به عنوان یک تیم گرد هم آمدیم تا Roblox را به زندگی بازگردانیم، و چگونه در هر مرحله از راه با همدیگر با ادب و احترام رفتار می کردیم.
ما از این تجربه بسیار آموختهایم و بیش از هر زمان دیگری متعهد هستیم که Roblox را به پلتفرمی قویتر و قابل اعتمادتر در آینده تبدیل کنیم.
مجددا تشکر می کنم.
¹ توجه داشته باشید که تمام تاریخها و ساعتهای موجود در این پست وبلاگ به وقت استاندارد اقیانوس آرام (PST) است.
پست بازگشت Roblox به سرویس 10/28-10/31 2021 به نظر می رسد برای اولین بار در وبلاگ Roblox.
Source: https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021/
- "
- 000
- 2021
- 7
- 9
- دسترسی
- در میان
- اضافی
- تنظیمات
- مزیت - فایده - سود - منفعت
- الگوریتم
- معرفی
- تحلیل
- علم تجزیه و تحلیل
- برنامه های کاربردی
- معماری
- دور و بر
- تصدیق
- خودکار
- دسترس پذیری
- باطن
- پهنای باند
- بهترین
- بلاگ
- تخته
- تنفس
- ساختن
- بنا
- کسب و کار
- نهانگاه
- ظرفیت
- مورد
- موارد
- علت
- ایجاد می شود
- چالش ها
- تغییر دادن
- کانال
- چک
- ابر
- رمز
- آینده
- ارتباط
- انجمن
- پیچیدگی
- محاسبه
- اعتماد به نفس
- ظرف
- ظروف
- ادامه دادن
- کمک
- راحت
- هزینه
- ایجاد
- بحرانی
- جاری
- وضعیت فعلی
- داشبورد
- داده ها
- مرکز دادهها
- مرکز دادهها
- از دست رفتن داده ها
- پایگاه داده
- پایگاه های داده
- تاریخ
- روز
- طرح
- کشف
- توسعه
- توسعه دهندگان
- در حال توسعه
- DevOps
- تشخیص
- DID
- رقم
- کشف
- کشف
- دی ان اس
- پایین
- مدت از کار افتادگی
- قطره
- کاهش یافته است
- در طی
- در اوایل
- لبه
- موثر
- انتخاب
- را قادر می سازد
- مهندسی
- مورد تأیید
- محیط
- واقعه
- گران
- تجربه
- شکست
- تقصیر
- ویژگی
- شکل
- سرانجام
- نام خانوادگی
- تمرکز
- به جلو
- رایگان
- کامل
- آینده
- سوالات عمومی
- مولد
- GitHub
- جهانی
- خوب
- در حال رشد
- رشد
- اداره
- سخت افزار
- سلامتی
- اینجا کلیک نمایید
- زیاد
- نگه داشتن
- چگونه
- HTTPS
- صدها نفر
- شناسایی
- تصویر
- تأثیر
- پیاده سازی
- مهمتر
- بهبود
- از جمله
- افزایش
- مستقل
- شاخص
- نفوذ
- اطلاعات
- شالوده
- وقفه
- بررسی
- تحقیق
- IP
- مسائل
- IT
- کار
- شغل ها
- پیوست
- کلید
- دانش
- بزرگ
- برجسته
- یاد گرفتن
- آموخته
- رهبری
- سطح
- سطح
- قدرت نفوذ
- کتابخانه
- محدود شده
- فهرست
- بار
- محل
- قفل
- طولانی
- نگاه
- دستگاه
- ماشین آلات
- عمده
- اکثریت
- ساخت
- مدیریت
- علامت
- متریک
- میلیون
- مدل
- پول
- مانیتور
- نظارت بر
- ماه
- بیش
- حرکت
- نزدیک
- شبکه
- شبکه
- سال نو
- گره
- خانه بدوش
- آنلاین
- باز کن
- منبع باز
- عملیاتی
- سیستم عامل
- عملیات
- سفارش
- دیگر
- قطع شدن
- مدیون
- ارام
- الگو
- پرداخت
- کارایی
- اصرار
- چشم انداز
- سکو
- بازیکن
- بازیکنان
- فقیر
- محبوب
- بنادر
- قوی
- فشار
- جلوگیری
- روند
- تولید
- پروژه ها
- پروتکل
- عمومی
- ابر عمومی
- انتشار
- Q1
- خام
- داده های خام
- كاهش دادن
- گزارش
- گزارش ها
- تحقیق
- منابع
- مسئوليت
- مسئوليت
- REST
- نتایج
- Roblox
- دویدن
- در حال اجرا
- s
- مقیاس
- مقیاس گذاری
- زمان بندی
- بخش ها
- انتخاب شد
- حس
- سلسله
- سرور
- محصولات
- خدمات
- به اشتراک گذاشته شده
- تغییر
- کوتاه
- نشانه ها
- سایت
- کوچک
- عکس فوری
- So
- فضا
- چرخش
- انشعاب
- ثبات
- شروع
- آغاز شده
- دولت
- ارقام
- ذخیره سازی
- opbevare
- پرده
- جریان
- فشار
- اشتراک، ابونمان
- متعاقب
- موفق
- پشتیبانی
- پشتیبانی
- افزایش
- زنده ماندن
- مظنون
- سیستم
- سیستم های
- استعداد
- فنی
- فن آوری
- پیشرفته
- می گوید
- آزمون
- تست
- La
- جهان
- از طریق
- زمان
- نیشگون گرفتن
- نقطه اوج
- با هم
- ابزار
- بالا
- ترافیک
- درمان
- تریاژ
- توییتر
- منحصر به فرد
- غیر معمول
- بروزرسانی
- به روز رسانی
- ارتقاء
- us
- ارزش
- طاق
- نسخه
- چشم انداز
- دید
- حجم
- هفته
- چی
- WHO
- پنجره
- در داخل
- کلمات
- مهاجرت کاری
- کارگر
- جهان
- با ارزش
- سال
- صفر